El principio de ventaja acumulativa enuncia que una vez que un agente o individuo consigue una pequeña ventaja sobre el resto de la población ésta tenderá a acumularse a lo largo del tiempo, mejorando así la situación del agente según la métrica que define esta ventaja. Este principio se resume bien mediante expresiones como "los ricos cada vez se vuelven más ricos", "el éxito engendra éxito" o si tomamos un tono más bíblico, el denominado principio de Mateo:
(...) al que más tiene más se le dará, y al que menos tiene, se le quitará para dárselo al que más tiene.
Enunciado de manera formal por Robert K. Merton a finales de los años sesenta, surgió como un modelo que describía cómo los científicos que al comienzo de sus carreras obtenían más publicaciones, conseguían, ya con sus carreras más avanzadas, un mayor éxito respecto al de sus colegas.
El principio de ventaja acumulativa fundamenta la desigualdad en la vida diaria. Partamos de una situación inicial en la que todos los sujetos son iguales, digamos que nos encontramos en un aula de primer curso en un colegio. Por el motivo que sea, el maestro trata de manera diferente a ciertos alumnos, ya sea beneficiándolos o perjudicándolos. Pese a que no suceda en todos los casos, aquellos alumnos que cuentan con el favor del maestro conseguirán mejores notas que aquellos que no cuentan con esta ventaja. Estas notas pueden llevar a que otros docentes también les tengan estima, mejorando su condición. Desgraciadamente, la situación contraria también se da: aquellos a los que se les tiene "manía" muy pocas veces llegan a alcanzar a aquellos que cuentan con el favor del maestro. No estoy diciendo que ésta sea la única variable que afecte al rendimiento escolar, pero pequeñas diferencias al inicio, como pueden ser el entorno familiar o académico cuando se es niño, reducen las oportunidades de alcanzar las metas en comparación con otros individuos que han tenido un comienzo más favorable. Es por eso por lo que esta situación de éxito o fracaso se autoperpetúa, ya que las generaciones posteriores heredarán parte de esta ventaja o desventaja inicial, siendo muy dificil frenar el ciclo.
Esta situación no sólo afecta a los primeros años de vida, sino que se refuerza cada vez que empezamos una nueva etapa. Por ejemplo, la obtención de un mejor primer empleo lleva a que se obtenga un mejor segundo trabajo y así sucesivamente. Dos personas muy similares, por puro azar pueden conseguir trabajos iniciales ligeramente diferentes, lo cual puede puede conllevar a que con el paso de los años uno de las personas esté en una situación mucho mejor que la otra, ya no sólo por azar inicial sino porque la secuencia de empleos le ha llevado a desarrollarse como mejor profesional, autoperpetuando esta situación inicial favorable. En marketing también se da esta situación y recibe el nombre de ventaja del primer movimiento ( first-mover advantage ) la cual explica cómo en ciertos nichos de mercado sin ocupar el que obtiene la ventaja es aquel que efectúa el primer movimiento respecto. Es siempre el mismo proceso: una ventaja inicial conlleva una leve mejora respecto al resto, inicialmente en un sólo aspecto pero termina afectando por completo al agente. Si retomamos el ejemplo de la situación laboral, quién consiguió el primer mejor trabajo puede que sea un mejor profesional al cabo de los años (lo cual puede verse como una mejora en el desarrollo cognitivo), pero también tendrá más dinero (mejora económica) y, tal y como están las cosas ahora mismo, podrá disponer de una mejor cobertura sanitaria ( mejora en la salud ).
Lo interesante es que la idea subyacente a este proceso es sencilla de simular por ordenador. Imaginemos una situación en la que tenemos una red de conexiones entre personas. Al comienzo la población es pequeña y todos se conocen entre sí, pero poco a poco introducimos nuevos individuos que se conectan a los ya presentes. La probabilidad de que un nuevo individuo se conecte a uno ya existente es proporcional al número de conexiones que ésta posee. Hemos dicho que inicialmente todos tienen las mismas conexiones, por lo que todos tienen la misma probabilidad de recibir un nuevo enlace. El video bajo estas líneas es la respuesta a esta situación: conforme pasa el tiempo los que inicialmente tuvieron la suerte de conseguir más enlaces se hacen cada vez más fuertes. Os recomiendo también que echéis un vistazo a este enlace en el que existe una versión interactiva del mismo proceso que se ve en el vídeo inferior.
Al final de lo que se dispone es de lo que se llama una distribución acorde a la ley de potencias. Lo que se traduce en términos comunes en que "hay muy pocos que tienen mucho y muchos que tienen poco". En la figura inferior se puede ver cual sería la distribución del número de enlaces (eje y) respecto al número de individuos (eje x) en una situación similar a la que veíamos en el video. Muy pocos (hacia la izquierda) poseen la mayor parte del area de la gráfica, mientras que existen muchos (hacia la derecha) que disponen de muy poco.
Aunque parezca un problema de juguete, nunca ha de olvidarse que sólo basta una pequeña diferencia producida por el azar en el comienzo de cada etapa de la vida de una persona para que el desarrollo de ésta se vea cambiado por completo.
La geometría euclídea (ya sea en dos o tres dimensiones) es una descripción idealizada del espacio que nos rodea, tal y como es percibido por nuestros sentidos. Aún así estos espacios no se limitan a tres dimensiones, ya sea porque el fenómeno a explicar requiere de más componentes o porque es una ficción conveniente representarlo de esta manera (véase el artículo de este mismo blog titulado la maldición de las dimensiones), por lo que estas representaciones que se escapan a la percepción humana no dejan de ser igualmente válidas desde un punto de vista analítico. En este artículo nos centraremos en la geometría de la realidad, incluyendo la dimensión temporal, por lo que hablaremos de resultados que se pueden generalizar fácilmente a cuatro dimensiones. Antes de comenzar, debemos asumir los siguientes principios:
Cada observador que mencionemos se asume que posee un reloj, el cual se encuentra sincronizado con el resto de relojes.
La línea de universo es la trayectoria que un cuerpo sigue a través del espacio-tiempo
Emplearemos dos dimensiones espaciales y una temporal. Los resultados se generalizan (pero no se visualizan) fácilmente a tres dimensiones espaciales y una temporal.
Nos limitaremos el movimiento uniforme. Los resultados pueden generalizarse a movimientos acelerados, sustituyendo las lineas de universo por curvas de universo.
El espacio-tiempo de Galileo
Esquema del espacio-tiempo galileano / Elaboración propia
Tenemos tres dimensiones espaciales, pero es útil disponer de una cuarta, temporal. Tiene sentido asumir que cada uno de los valores de la dimensión temporal tiene asociada una visión del estado, de la configuración de esas tres dimensiones espaciales. Ése es el significado del espacio-tiempo de Galileo. En cada instante distinto, una partícula, cuerpo puede ocupar, si está en movimiento, una posición distinta, o bien si se da el caso de que permanece en reposo, puede ocupar la misma posición que en el instante anterior. En la figura de la derecha puede verse un ejemplo de este tipo de geometría. Las líneas azuladas muestran la trayectoria de tres cuerpos. La trayectoria A se corresponde con un cuerpo en reposo, por lo que su línea de universo es paralela al eje temporal. Las trayectorias B y C se desplazan con movimiento uniforme, pero su línea de universo es distinta (la trayectoria).
Imaginemos que somos el observador A, que convenientemente se encuentra en reposo en el mismo punto durante los tres instantes de tiempo que hemos marcado en el diagrama. Al comienzo, B estará más lejos de nosotros que C, situación que continuará en t=1. Finalmente, en t=2, B será la partícula más cercana.
El movimiento que experimenta cada una de las partículas a lo largo del tiempo es su velocidad y es posible su medida. En este caso concreto podemos asumir que las velocidades de B y C tienen la misma magnitud, pero como se aprecia en el diagrama, la dirección es la contraria (uno se mueve de derecha a izquierda y el otro de izquierda a derecha). Al encontrarse el observador A en reposo, el cómo aprecia el movimiento de B (es decir, su velocidad) será distinta a la que por ejemplo experimenta B respecto de A. Por ejemplo, es totalmente válido que B considere que quien se está acercando a una gran velocidad es A, en lugar del caso contrario.
Aunque no sea ninguna sorpresa, la capacidad de cambiar el sistema de referencia es tipo de relatividad, que ya se conocía en el siglo XVII. Lo interesante es que el paso de un sistema de referencia (originalmente A era la referencia y ahora lo es B) a otro se limitaba a sumas y restas entre los vectores de velocidad, es decir, a efectuar transformaciones rígidas como la traslación y rotación, necesarias para poder centrar el sistema de coordenadas en la partícula que queríamos considerar en reposo. Básicamente el principio de relatividad de Galileo se traduce en que no existe un marco de referencia (origen de coordenadas) mejor que otro, sino más conveniente según el propósito que se quiera analizar.
Como se ha podido ver no hemos mencionado nada sobre el tiempo, que sólo ha sido incluido como un elemento conveniente, muy útil para modelar un sistema dinámico. Las velocidades pueden ser relativas, pero para todos los elementos del sistema el tiempo transcurre de la misma forma, el tiempo es absoluto, por lo que pasa para todos los observadores al mismo ritmo. Además todos los cuerpos se sienten como en una autovía alemana: no tienen límite de velocidad. ¿Por qué debería haberlo? En el siglo XVII bien daba igual que una bola cayese a 80 km/h que a 240 km/h, son velocidades ridículamente lentas. La ciencia moderna prácticamente acababa de nacer, no existían los medios para preocuparse para velocidades realmente elevadas.
En general, esta geometría es válida y se corresponde a la realidad que percibimos con los sentidos. El problema surge cuando los cuerpos se desplazan a grandes velocidades. Es en ese caso cuando este espacio-tiempo comienza a romperse.
El espacio-tiempo de Minkowski
La idea de que la concepción galileana era errónea surgió a partir de los experimentos de Michaelson-Morley, que concluyeron que la velocidad de la luz era exactamente la misma, independientemente del sistema de referencia empleado. La idea principal era que si la fuente de luz se movía en dirección opuesta al aparato de medición, debía sumarse la velocidad relativa que llevaba el aparato en cuestión. Se vio que eso no pasaba, la velocidad de la luz era siempre la misma. Nunca se sumaba ni se restaba nada.
El cono de luz de Minkowski / Elaboración propia
Hermann Minkowski fue el autor de una nueva geometría en la cual el espacio y el tiempo se encontraban fundidos de manera completa, no como en el caso de la geometría de Galileo. El elemento central de la geometría de Minkowski es el cono de luzque incrusta en la estructura espacio-temporal un límite de velocidad, el de la luz. El cono simboliza la trayectoria más rápida que cualquier partícula puede adquirir. En un extremo, el del reposo, el cuerpo sigue el eje temporal y en el extremo opuesto, cuando la partícula se desplaza a la velocidad de la luz, la trayectoria está en la superficie interna del cono. Cualquier velocidad intermedia se encuentra, por lo tanto, entre el centro del cono y la superficie de éste.
En la figura a la derecha de estas palabras se muestra este cono. Las líneas de universo denominadas P1 y P2 se encuentran en el borde interno del cono, por lo que se corresponden con fotones, los cuales se desplazan a la velocidad de la luz. La trayectoria denotada mediante una línea discontinua (R) se corresponde a un cuerpo que se desplaza rápidamente, al menos comparado con la línea azul, denotada mediante la letra M. Por ahora, salvo a la imposibilidad física impuesta por el cono, no hay mucha diferencia entre la geometría galileana y la minkowskiana. Pero si la hay, porque esta estructura altera la manera en la que se mide la distancia entre dos sucesos (no puntos, sucesos). Veamos cómo se mide la distancia en la geometría euclidiana (en dos dimensiones) y en la minkowskiana (dos dimensiones espaciales y una temporal).
En el caso de la geometría euclidiana hemos asumido que sólo tiene dos dimensiones, por lo que la expresión indica la distancia entre ese punto (x,z) y el origen. Sin embargo, en el caso de la geometría que da título a esta entrada, t denota el tiempo experimentado por un observador en reposo, es decir, respecto al sistema de coordenadas (hecho que puede verse en la figura anterior).
El resto de las componentes representan la velocidad a la que se desplaza el cuerpo, relativa eso si, a la velocidad de la luz. Esta ecuación plantea varios escenarios. Si el observador está en reposo respecto al marco de referencia, entonces tanto x como z (junto con y, si lo extendemos a tres dimensiones temporales) serán cero, por lo que la distancia entre dos sucesos será equivalente al tiempo transcurrido desde el punto de vista de un observador en reposo (lógico, porque está en reposo). Sin embargo, conforme la velocidad se acerca a c, los elementos que restan se van haciendo cada vez más grandes, disminuyendo el tiempo percibido, entre los dos sucesos. El extremo opuesto a la situación de reposo sería el caso de una partícula que se desplace a la velocidad de la luz. En este caso s pasaría a valer cero. De esta manera se afirma que, para un fotón, el tiempo no transcurre. Todavía queda el caso en el que el cuadrado de s es un número negativo. Esto sería equivalente a que estuviera fuera del cono y bueno, eso ya lo veremos en otra entrada. Repito un hecho muy importante, el significado de s es el de tiempo percibido, tiene sentido que ésta sea la distancia porque es una geometría de espacio-tiempo.
Esta manera de medir las distancias en el espacio-tiempo tiene una característica que parece contradecir la intuición. Si tenemos tres puntos, A, B y C, estamos acostumbrados a que la distancia entre dos de ellos, digamos A y B, sea como mucho igual que la suma de las distancias entre A y B junto con la de B y C. Esta expresión es denominada desigualdad triangular y es una propiedad que cumple la geometría euclídea, sin importar el número de dimensiones que la describan. El problema es que la geometría de Minkowski, el triángulo descrito por A, B y C cumple la expresión siguiente:
Esquema de la paradoja
de los gemelos /
Elaboración propia
Expliquemos el significado de (2) con un ejemplo, la archiconocida paradoja de los gemelos. El escenario es el siguiente. Existen dos gemelos, uno de ellos permanece en la Tierra mientras que su hermano se monta en una nave espacial y realiza un viaje a una cierta velocidad, para luego retornar a la tierra. Imaginaremos que el retorno no implica ningún tipo de parada y que la nave sigue una velocidad constante durante todo el trayecto. Existe un suceso, A, el cual es el comienzo del viaje y otro, C, el cual es el retorno del gemelo. El suceso B implica el instante en el espacio-tiempo en el comienza el viaje de vuelta.
Situando el origen de coordenadas en A, podemos afirmar que entre A y C, para un observador en reposo pasan t unidades de tiempo. Sin embargo, entre A, C y luego C, B el hermano se desplaza a una cierta velocidad, la cual llamaremos v_m. Ahora combinaremos la definición de s vista en la expresión (1.2), con la relación entre las distancias vista en (2) para ver que, en efecto, el gemelo viajero experimenta menos tiempo. Para ello denotaremos como v_r a la velocidad en reposo, cuyo valor es cero y como v_m a la velocidad en movimiento, cuyo valor no es necesario determinar para afirmar que la desigualdad vista en (2) se cumple en sentido estricto.
A no ser que v_m valga también cero, el mero hecho de que el segundo gemelo se desplace fuerza a que la desigualdad se decante hacia el lado de la suma. Por este motivo la geometría no es euclidiana, porque la medida distancia no cumple la desigualdad triangular. Además, debido a que ambos gemelos han experimentado un tiempo distinto, puede decirse que el tiempo es relativo. Aún así todo esto no quiere decir que la concepción de Galileo sea incorrecta. Es correcta siempre y cuando las velocidades sean pequeñas respecto a la de la luz. Este hecho se puede ver en (3), en el que si v_m es pequeño, el tiempo percibido es muy similar al que experimenta el gemelo en reposo. Lo que esta geometría nos enseña es que el tiempo no es absoluto y que se encuentra fundido de una manera mucho más intrincada de lo que se pensaba originalmente. Y si has llegado hasta aquí, enhorabuena ;) Pepe "Puertas de acero" Pérez
[Esta es la primera parte de dos entregas relacionadas con la criptografía. Esta entrada tiene como objetivo explicar cuáles son algunas de las técnicas tradicionales, así como dar una visión general de la labor de la criptografía. El viernes habrá otra publicación que tratará sobre el comportamiento de los sistemas criptográficos modernos, es decir, aquellos que empleamos a diario desde nuestros ordenadores]
La escítala, una de las primeras técnicas de cifrado de la Historia / Eivind Lindbråten
Desde que el ser humano comenzó a comunicarse ha existido el deseo de que la información intercambiada se enmascarase de tal manera que posibles fisgones no pudieran comprender su significado. Algunos de nosotros hemos utilizado códigos a lo largo de nuestra vida, si bien de manera informal. Es hora de que veamos cómo se ha llevado a cabo la práctica de enviar secretos, desde un punto de vista más metódico.
La criptografía puede considerarse la rama de la ciencia que se encarga de realizar transformaciones sobre el lenguaje de los mensajes, de tal manera que lectores no autorizados sean incapaces de comprender su contenido. Un sistema criptográfico es la entidad encargada de aplicar una serie de transformaciones sobre un mensaje en claro (plaintext), para producir un criptograma o mensaje cifrado (cyphertext). Las transformaciones que se aplican son matemáticas, por lo que es imprescindible tener claro que cada letra puede representarse mediante un número distinto, sobre el cual pueden aplicarse operaciones, como la suma o la resta, para luego volver a la representación en forma de caracteres. Por ejemplo, a la letra A se corresponde con el número cero, la B con el uno y así sucesivamente. La potencia de esta asociación entre números y letras radica en las ventajas que aporta un marco formal.
La naturaleza de los sistemas criptográficos ha ido evolucionado con el paso del tiempo. En el siglo V a.C ya existían técnicas como la escítala o el cifrado Atsbahque permitían la codificación de mensajes. En general, estos procedimientos basaban su funcionamiento en la sustitución de cada una de las letras del abecedario por otra distinta, siguiendo una regla fija. A partir del conocimiento de los pasos seguidos para el cifrado, era posible recuperar el mensaje original. Debido a que estas técnicas emplean un único alfabeto alternativo para codificar el mensaje se denominan técnicas de sustitución monoalfabética, de entre las cuales destacamos el cifrado César.
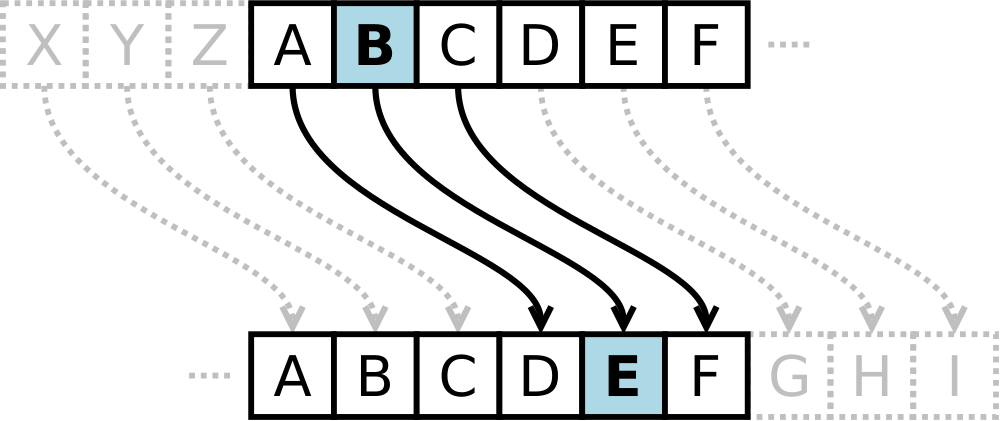
El cifrado César sustituye cada letra del mensaje original por aquella letra que se encuentra a k unidades de la letra original, por lo que la regla empleada no es fija (como sucedía con el cifrado Atsbah), sino que dispone de una variable: el desplazamiento ka llevar a cabo. Por ejemplo, si k=3 la sustitución que se aplica a cada una de las partes del mensaje puede verse reflejada en la figura que se encuentra bajo estas líneas.
Sustitución monoalfabética con desplazamiento k=3 / Cepheus
Para este caso concreto, A pasa a ser B, C se transforma en E y así sucesivamente. Las últimas letras (X, Y y Z) se convierten en las tres primeras respectivamente (A, B y C). Una ventaja muy importante de este procedimiento de cifrado es que el mero conocimiento de la regla empleada para cifrar es inútil por sí sólo, porque también es necesario conocer el valor de k con el que se había cifrado el mensaje original. De manera muy sencilla, ese valor de k constituye un secreto compartido, una clave, que solo los interlocutores designados deben conocer. A continuación puede verse un ejemplo de texto original y su correspondiente texto cifrado.
Texto original: Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat.
Como puede apreciarse, el resultado es completamente ininteligible, motivo por el cual las legiones romanas empleaban este esquema de cifrado para ocultar el contenido de sus mensajes. Su utilidad en dicho contexto histórico fue el que instigó los rumores de su uso por parte de Julio César, del cual toma su nombre.
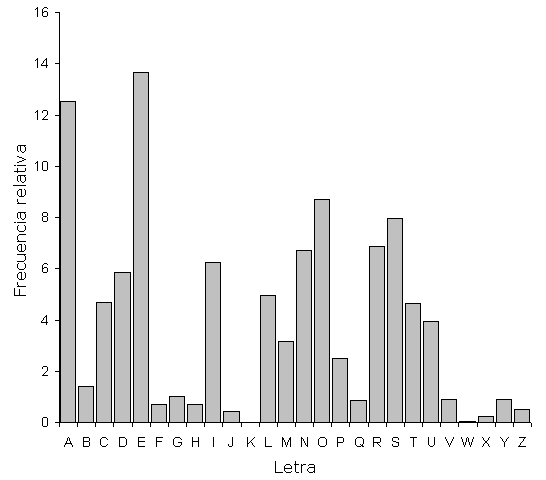
Esta técnica se encuentra en desuso desde principios del año 1000 d. C. El motivo es que aplicar un desplazamiento a cada una de las letras, a primera vista produce resultados ininteligibles, pero deja intactos los patrones presentes en el texto original. Esto es debido a que las letras empleadas para comunicarse en un cierto idioma siguen una determinada distribución de frecuencias, es decir, puede saberse la proporción aproximada con la que aparece una determinada letra en un idioma concreto. Para comprender mejor lo que se quiere decir con distribución de frecuencias, puede verse a continuación un ejemplo de histograma de frecuencias para el idioma español.
Histograma de frecuencias para el español / WIKIPEDIA
El histograma situado a la izquierda se ha calculado a partir de varios textos en español y, para cada letra, indica el porcentaje de veces que aparece. Si lleváramos a cabo un cifrado César la única diferencia entre el histograma calculado a partir del mensaje sin cifrar y el obtenido a partir del cifrado, sería un desplazamiento en la distribución de frecuencias. Por ejemplo, el pico que se observa en la A pasaría a encontrarse kletras después, por lo que si construimos este histograma a partir de textos cifrados, el problema de encontrar la k empleada se transforma en encontrar el desplazamiento de los picos. En general, a la primera puede que el desplazamiento adivinado sea incorrecto, pero es posible encontrarlo con relativa facilidad, simplemente intentando averiguar a dónde han ido a parar los picos correspondientes a las letras más frecuentes. El problema se simplifica si se emplean ordenadores, ya que ni siquiera necesita calcularse un histograma porque la máquina es lo suficientemente potente como para descifrar el texto con todos los valores posibles de k y comprobar con cual de ellos se obtiene un texto con sentido.
Esta técnica para averiguar la clave empleada en cifrados como el anterior recibió el nombre de análisis de frecuencias. Los cifrados de sustitución monoalfabéticos quedaron inservibles, pero persistía la necesidad de comunicarse de manera secreta, por lo que aparecieron nuevas técnicas. Si en este tipo de cifrados sólo se empleaba un alfabeto, es decir, para cada mensaje sólo se disponía de un alfabeto alternativo, que era el mismo que el original pero desplazado k unidades, el paso siguiente era usar más alfabetos. Es decir, que a una misma letra no le correspondiese siempre la misma cifrada, sino que hubiera alguna alternativa.
Si se emplean varios alfabetos, el histograma de frecuencias no guarda ningún parecido porque cada una de las letras sigue un cifrado independiente al resto. Por este motivo, este tipo de cifrados reciben el apelativo de polialfabéticos ya que emplean varios alfabetos. La más sencilla de estas técnicas recibe el nombre de cifrado Vignère y fue planteado en 1553. La idea principal de esta técnica es utilizar para cada letra del mensaje original un cifrado César distinto. Debido a que cada letra se codifica de manera independiente necesitamos un elemento adicional, la clave, que es mucho más compleja que la k empleada en el cifrado César.
Veamos un ejemplo. Necesitamos dos elementos para cifrar, el primero de todos es el mensaje a transmitir. En este caso escogemos una palabra de actualidad, SOBRESPARATODOS. Para poder cifrarla necesitamos una clave, la cual escogemos que tome el valor de AMIGOS. Aquí surge el primer problema, la clave debe ser igual de larga que el mensaje a cifrar, por lo que es necesario expandirla. Este proceso de expansión consiste en rellenar el final de clave con el principio de la misma, hasta que la longitud sea idéntica a la del mensaje. La clave extendida sería entonces AMIGOSAMIGOSAMI.
Una vez establecidos estos parámetros de entrada, el cifrado Vignère recorre el mensaje original y la clave al mismo tiempo. De tal manera que en cada paso de cifrado se dispone de una letra del mensaje original y otra letra de la clave. Para cifrar la letra del mensaje se calcula la posición que ocupa en el alfabeto el carácter de la clave. Esa posición es el valor k que emplea para cifrar (mediante cifrado César) la letra correspondiente del mensaje.
Proceso de cifrado Vignère para las tres primeras letras del mensaje SOBRESPARATODOS, empleando para ello la clave AMIGOS / Elaboración propia.
En la figura anterior puede verse como a la S (primer carácter del mensaje) le corresponde el ordinal 18 y a la A (primera letra de la clave) el número 0. La suma de ambos resulta en el ordinal 18 (esto es, hemos aplicado un cifrado César sobre la letra del mensaje), el cual se corresponde con la letra S. El proceso se repite para la segunda posición de la clave y el mensaje. La letra O se corresponde con el ordinal 14 y la M con el ordinal 12 que sumados producen el número 26. Debido a que hay exactamente 26 letras (desde 0 hasta la 25) la letra 26 es equivalente a la letra cero (el resto de dividir 26 entre 26 es cero, es como si la suma diera la vuelta, volviendo a empezar a partir del 26), por lo que se obtiene la A como resultado. La figura anterior concluye con el resultado de cifrar la tercera letra, la B, con la tercera letra de la clave, la I. En este caso la suma resulta en 9, lo cual equivale a la letra J. El proceso se repite para cada una de las letras del mensaje. Los elementos involucrados en el proceso pueden verse a continuación:
texto: SOBRESPARATODOS
clave: AMIGOS
cifrado:SAJXSSBIXOTALUG
Debido a que este tipo de cifrado intenta usar una letra distinta para cifrar cada parte del mensaje, su fortaleza su mantuvo hasta 1863, cuando Friedrich Kasiski determinó que algunos patrones típicos del texto en claro seguían apareciendo en el texto cifrado. Esto se debe a que la clave suele ser, en la mayoría de los casos, más corta que el mensaje. Este hecho fuerza a que la clave tenga que extenderse, repitiéndose fragmentos a lo largo de la misma. Entonces es cuando, por azar, es posible encontrarse letras iguales del texto en claro por fragmentos iguales (repetidos) de la clave. De esta manera algunos patrones pueden aparecer en el texto cifrado y es posible reconstruir la clave que se empleó.
Estas técnicas no son complejas, pero dominaron gran parte de la historia de la criptografía. Este viernes veremos cómo hemos pasado de estos esquemas de cifrado tan básicos a disponer de comunicaciones seguras en Internet.
Búsqueda de la solución correcta. Imagen tomada por Lynne Hand.
Esta semana el tema que escogido es la computación cuántica. Este es un tema complicado, por lo que el objetivo de esta entrada es otorgar una visión intuitiva del proceso y las posibilidades que éste abre a la computación. Para ello es necesario introducir ciertas nociones acerca de los sistemas cuánticos. Como esto es Internet, reino de los gatos, el ejemplo con el que comenzamos es el experimento mental llevado a cabo por Erwin Schrödinger en 1935. Sí señores, vamos a hablar del gato de Schrödinger.
Como este experimento ha sido explicado hasta la saciedad en distintos blogs, intentaré ser breve. Imaginemos que se dispone de una caja, en la cual se ha depositado un gato. Además se ha incluido un emisor de partículas alfa con su correspondiente detector, un martillo y un frasco de veneno. El proceso es el siguiente: cuando se detecta una partícula, el detector libera el martillo que golpea el frasco de veneno, lo cual libera su contenido, matando al animal. No obstante, hay que tener en cuenta los siguientes puntos:
El gato no puede interferir en la emisión de las partículas, ni impedir que si se detecta alguna, la botella se rompa.
La caja se encuentra completamente aislada del mundo exterior. No es posible saber lo que está sucediendo o lo que ha sucedido sin abrirla.
El emisor de partículas en cada instante de tiempo puede, con la misma probabilidad, tanto emitir una partícula como no hacerlo.
El problema planteado es saber, sin mirar el interior de la caja, si el gato está vivo o muerto. Unos podrían pensar que el gato se encuentra vivo, porque el emisor no ha desencadenado la rotura del frasco de veneno. Pero es igualmente válido pensar lo contrario, que se encuentra muerto, ya que la probabilidad de que el veneno se derrame es idéntica a que permanezca intacto. Está claro que al ser incapaces de abrir la caja no podemos afirmar con certeza cual es el estado del gato. De manera algo más formal, el estado del gato puede verse en términos de la siguiente expresión:
Básicamente la expresión quiere decir que el gato está vivo con una probabilidad de un medio y muerto con la misma probabilidad. El estado final del gato es una superposición, con la misma probabilidad, de dos sucesos mutuamente excluyentes. Entonces, ¿significa ésto que el gato está vivo y muerto a la vez?
Un gato no puede estar vivo y muerto a la vez, por lo que existen varias interpretaciones a este fenómeno. Una de ellas (la interpretación de Copenhague de la mecánica cuántica) afirma que lo sucedido es fruto de la incapacidad de determinar en cual de los dos estados se encuentra el gato, sin realizar una observación del sistema, que en este caso, consiste en abrir la caja. Conocemos bien las condiciones iniciales, pero conforme el tiempo pasa sólo disponemos de probabilidades. Aún así, cuando abrimos la caja, el estado de la expresión (1) se colapsa a uno de los dos posibles: vivo o muerto, con la probabilidad correspondiente. Que quede claro, el gato no está vivo o muerto a la vez, es la incapacidad de conocer el estado real del sistema la que nos obliga a emplear probabilidades. Lo mismo sucede cuando manipulamos sistemas en los que intervienen partículas subatómicas, como si de una caja se tratara, no podemos conocer a ciencia cierta lo que está pasando hasta que tomamos la decisión de echar un vistazo al resultado.
Por ahora se ha visto que un sistema cuántico tiene un estado interno el cual no está completamente determinado y un estado observado, el cual se aprecia tras efectuar la medida correspondiente. Olvidémonos un rato del gato y asumamos que tenemos dos estados abstractos, 0 y 1. Realmente no importa el nombre, la clave es que sean mutuamente excluyentes. El significado de cada uno de los valores se deja a la imaginación del lector, puede significar vivo o muerto, encendido o apagado, verdadero o falso, etc.
Mediante dos estados claramente diferenciados, es posible almacenar un bit de información. Este sistema constituye el pilar de la teoría de la información en la computación clásica, por ello los ordenadores convencionales manejan bits, que pueden tomar valores de 0 o 1. Por el contrario, en la computación cuántica disponemos de otra unidad de información, el qubit, que se corresponde con un sistema cuántico regido por la siguiente expresión:
Hay una enorme similaridad estructural con la expresión que determinaba el estado del gato, de hecho sólo cambia el nombre de los estados (vivo ha pasado a llamarse cero y muerto ha pasado a llamarse uno), además de que los pesos pueden tomar cualquier valor. De hecho, el sistema cuántico del gato de Schrödinger sólo necesita un qubit para ser representado. La potencia de la expresión anterior viene de que un qubit puede encontrarse en una superposición continua. Entendemos por superposición a que los valores que puede tomar son una combinación de las posibles situaciones. Esta combinación también viene determinada por los valores que toman alfa y beta, que determinan la probabilidad del resultado de la medición. Es decir, si alfa toma un valor de 0.9 y beta de 0.1, al realizar la medición del sistema, 9 de cada 10 veces el resultado será cero y 1 de cada 10, será 1.
El primer reto que debe superar la computación cuántica es cómo operar con sus unidades básicas de información. En la computación clásica, las operaciones elementales son aquellas que provienen de la lógica, por lo general, un 1 representa cierto y un 0 representa falso, por lo que puede calcularse la conjunción de dos bits (a Y b), la disyunción (a O b) y la negación (NO a). En principio, con esas tres operaciones puede construirse cualquiera más compleja. Por eso se dice que esas tres operaciones, y su implementación física, son universales. Ahora bien, en el mundo cuántico un qubit puede contener información acerca de los dos estados simultáneamente, por lo que existen operaciones más complejas que aprovechen esta naturaleza. Por lo tanto, los algoritmos cuánticos deben aprovechar que un qubit puede estar tanto en el 0 como en el 1 para realizar cálculos en paralelo. Este tipo de paralelismo se basa en que mientras, por así decirlo, no "miremos" el estado, la información puede estar repartida en varios sitios a la vez. Un algoritmo que maneje un qubit podrá manejar dos valores en paralelo, pero si es de dos qubits el número se duplica, pasando a ser cuatro. En general, se incrementa el número de qubits en una unidad, las posibilidades se ven duplicadas. Esto incrementa el grado de paralelismo hasta niveles inimaginables por los computadores tradicionales. Eso si, al igual que cuando abríamos la caja del gato la magia desaparecía y conocíamos la salud del gato, aquí sucede lo mismo, por lo que las operaciones a realizar deben realizarse sin realizar observaciones sobre el estado.
Ahora bien, realmente no sabemos qué es un qubit. En principio, es posible afirmar que son un concepto matemático, al igual que sucede los bits clásicos. Mientras que estos últimos se llevan a la práctica mediante transistores (en la mayoría de los casos), en el caso de un qubit no se ha encontrado todavía una implementación física definitiva. En algunos casos se representan mediante el spin de un electrón, del núcleo atómico o incluso la polarización de un fotón. En cualquier caso, las magnitudes anteriores tienen dos valores definidos y mutuamente excluyentes pero su naturaleza cuántica (estamos al nivel de fotones y electrones) permiten una superposición de ambos estados, lo cual se corresponde con la idea matemática de un qubit.
Ahora bien, si esta implementación física de los qubits fuera tan sencilla, ya dispondríamos de ordenadores cuánticos comerciales, pero todavía existen muchos problemas que afrontar. Uno de los más importantes es el fenómeno conocido como decoherencia. Por así decirlo, el estado del sistema se filtra al entorno que le rodea, por lo que para evitar que las computaciones se desmoronen es necesario aislar completamente el sistema, o al menos hacer que éstas se realicen lo suficientemente rápido. Veamos qué papel juega la decoherencia en la computación
Idealmente la computación cuántica seguiría el proceso siguiente. En primer lugar se traduce la información clásica a qubits. Esto es posible porque un bit es un caso particular de qubit, en el que alguno de los coeficientes, ya sea alfa o beta, vale cero. A lo largo del computador se procesa la información. Mediante una serie de transformaciones, el estado cuántico se modifica, lo cual puede verse en un cambio de valores en los parámetros alfa y beta, por lo que aprovechan la naturaleza cuántica. Finalmente se realiza el proceso de observación, lo cual colapsa el estado cuántico en uno de sus posibles valores. Es vital mencionar que el procesamiento dentro del computador es completamente determinista. Existe una regla de evolución que dicta claramente como cambian los pesos de los distintos estados, mientras que el no determinismo surge al realizar la observación. Es por lo que los algoritmos diseñados para ejecutarse en un computador cuántico deben obtener una cierta probabilidad de obtener el resultado correcto, es decir de todos los posibles resultados que conforman el estado superpuesto, aquel que es correcto debe ser el que más probabilidad tenga antes de colapsar el estado.
El problema es que durante la computación, parte de la información del estado cuántico se intercambia con el entorno, es decir, la decoherencia echa a perder los resultados. En cierto modo un computador cuántico trabaja como un operario ciego en una cadena de montaje. Sabe perfectamente qué tiene que hacer, pero es incapaz de ver el resultado de sus acciones, además de que el resto del entorno debe de desconocer también qué es lo que se está haciendo. Para mitigar este fenómeno, (el problema no se encuentra ni mucho menos resuelto) no es de extrañar que el computador cuántico puesto a la venta por la empresa canadiense D-Wave se encuentre dentro de un armazón criogénico de 10 metros cuadrados y valga 10 millones de dólares. Serious Business.
Finalmente merece la pena comentar en qué situaciones se han encontrado algoritmos cuánticos que ofrecen (en teoría) mejores prestaciones que los clásicos. La primera de ellas, aunque parezca la más evidente, es la posibilidad de simular sistemas cuánticos. Actualmente simular la evolución de un sistema de este tipo es enormemente costosa, tanto en términos de tiempo como de memoria. Por el contrario, un computador cuántico es capaz de simular procesos cuánticos, ya que realiza las computaciones en los mismos términos que el sistema que simula. Otra aplicación vital es la descomposición de números en el producto de sus factores primos. De hecho, esta es la aplicación más notable, ya que llevada a la práctica destrozaría los procesos de cifrado que empleamos a diario. Nos recuperaríamos, pero habría que cambiar bastantes cosas. Curiosamente el año pasado se consiguió descomponer el número 15 en sus factores primos, 3 y 5. El experimento se repitió casi 150.000 veces y consiguió acertar el 48 % de las veces. Parece ridículo, pero es un comienzo.
Además de los dos casos anteriores, existen numerosos algoritmos cuánticos en distintos dominios, como pueden ser búsquedas en bases de datos, bioinformática, etc. Desgraciadamente, la mayoría de los logros han sido conseguidos en el ámbito teórico, siendo aún pocas las aplicaciones prácticas. De todas maneras, al igual que los computadores clásicos nos han ayudado a entender la mecánica clásica, sus homólogos cuánticos pueden constituir una valiosa guía para comprender cómo funciona la mecánica cuántica, la cual es un dominio bastante incierto. Realmente, mi opinión sobre el tema es que debido a la naturaleza probabilista de la mecánica cuántica, no creo que este nuevo paradigma reemplace al actual, sino que será empleado en aquellos dominios donde la computación tradicional no rinda lo suficiente.
Si quieres saber más
Una clase íntegra de introducción a la computación cuántica, impartida por el Instituto de Computación Cuántica (Institute for Quantum Computing, IQC) de la Universidad de Waterloo en Canada. Lleva matemáticas de las chulas, avisados estáis.
El libro "An Introduction to Quantum Computing" por los autores Philip Kaye, Raymond LaFlamen y Michele Mosca. Es un libro serio, de hecho, el que imparte la clase anterior es uno de los autores.
Wikipedia muestra las distintas interpretaciones del resultado del experimento mental de Schrödinger. Puede consultarse en el siguiente enlace:
En este vídeo, un señor británico de dudosa dicción da un breve repaso sobre cómo representar los qubits, sus problemas y las aplicaciones que este modelo de computación puede aportar a la humanidad
Tras mi desapercibida desaparición de la semana pasada, vuelvo para hablaros de más cosas de informática. Esta vez, la última durante un tiempo, de lo que toca es hablar sobre la maldición de las dimensiones, termino acuñado por Richard Bellman en 1961. Como siempre, en esta entrada se sacrificará el rigor, con el objetivo de que este problema sea comprensible.
A grandes rasgos, la maldición de las dimensiones se refiere a una serie de fenómenos que suceden cuando se trabaja con espacios vectoriales de gran dimensión. De manera rápida y poco formal, un espacio vectorial es como una caja, llena de etiquetas, donde cada una de ellas contiene información codificada en forma de listas de números. Es importante mencionar que estas etiquetas se denominan vectores y que el número de números (valga la redundancia) que están escritos en cada etiqueta viene dado por la dimensión del espacio.
Así, por ejemplo, podríamos ver el espacio tridimensional que nos rodea como una caja donde todas sus etiquetas se encuentran escritas de la forma (x,y,z). Tanto x, como y o z, pueden tomar cualquier número real, pero cada combinación de las tres debe ser única. Estas dimensiones tienen un significado físico, ya que representan el desplazamiento en cada uno de los tres ejes que empleamos como sistemas de referencia, es decir, el número de direcciones independientes que hay: arriba/abajo, izquierda/derecha y adelante/atrás. A lo largo de esta entrada emplearemos el término vector, individuo indistintamente. Cada uno de los números de un vector los denominaremos como atributo o componente.
Si bien nuestros sentidos sólo perciben hasta tres dimensiones espaciales, tiene sentido hablar de más dimensiones con el objetivo de codificar características sobre elementos de nuestro interés. En un espacio de cuatro dimensiones, dispondríamos, por así decirlo, de cuatro números para caracterizar lo que quisiéramos Por ejemplo, podríamos ver a una persona como un vector cuyas cuatro componentes fueran las siguientes.
persona = (altura, peso, cociente intelectual, ingresos)
Con múltiples muestras de esta información podríamos hacer muchas cosas, como, por ejemplo, determinar si tiene estudios universitarios. La dura realidad es que existen aplicaciones en las que cada uno de sus "individuos" no puede ser descrito con tres o cuatro dimensiones, sino que puede necesitar del orden de miles o millones de ellas.
Esto plantea un problema: el volumen de una región crece de manera desproporcionada a lo que es la dimensión del mismo. Lo que es lo mismo, el volumen de un cubo de dimensión tres, es minúsculo comparado con un cubo de dimensión, digamos, 10. Además, la distribución de este volumen también cambia, hecho que se ve reflejado en la figura que sigue a estas líneas.
Efectos del incremento en el número de dimensiones sobre el volumen de una región. Extraído de [2].
Aquí se ve el cubo unidad (aquel cubo que tiene de lado una unidad) y una pequeña región, de la misma forma, en su interior. La gráfica de la derecha, muestra en el eje x la fracción de volumen contenida a la distancia que se aprecia en el eje y.
Básicamente, los distintos trazados muestran como esta relación varía para distintas dimensiones. Conforme nos desplazamos hacia arriba en la gráfica, es como si estiráramos todos los lados del cubo a la vez, hasta llegar a uno, momento en el cual el volumen de la región alcanzaría el del cubo unidad.
Un cubo de dimensión uno, es una línea recta, por lo que su "volumen" se va llenando hasta llegar a uno, de manera lineal, es decir a cada paso que incrementamos el lado, el volumen cubierto es proporcional.
El caso de dos y tres dimensiones (un cuadrado y un cubo, respectivamente) el volumen de la vecindad no se llena proporcionalmente, pero sigue siendo aceptable la distribución respecto de la distancia al centro. Finalmente, y es aquí donde se empieza a hacer patente la maldición, para el caso de 10 dimensiones, más de la mitad del volumen (52%) se encuentra más cerca de la frontera que del centro (recordemos que la distancia máxima es uno). Estas perspectivas empeoran conforme la dimensión aumenta, pudiendo afirmar sin miedo que casi todo el volumen de una región p-dimensional se encuentra en sus bordes.
Para entender esto hay que desligarse de la concepción que tenemos del volumen. Cuando pensamos en un cubo, pensamos que el volumen está contenido cerca del centro (¡y así es!), porque el volumen cercano al borde es muy fino. Esta afirmación sigue cumpliéndose para cubos de dimensión superior, sólo que en este caso el borde pese a seguir siendo fino, también es enorme. Pese a que sea fino, es tan vasto que acapara todo el volumen de la región.
Si los individuos de nuestro problema se encuentran en un espacio con muchas dimensiones, surgen los dos problemas elementales siguientes:
¿Como es posible disponer de medidas estadísticas significativas? Si tenemos un número moderado de muestras, pero muchísimas dimensiones, cada una de ellas cubrirá una porción pequeña del espacio. Esto plantea el problema de que es necesario incrementar el número de muestras para poder sacar conclusiones. Esto es un problema porque, por lo general, las muestras o ejemplos son difíciles de conseguir en el mundo real.
¿Como medimos la similitud entre individuos? Esto se relaciona directamente con la figura anterior. Por lo general, existen métodos que predicen el resultado calculando la distancia (puede verse la distancia entre dos puntos como lo similares que son) de un nuevo ejemplo respecto de los ejemplos que se conocen. Para esto se basa en encontrar qué vecino se encuentra más cerca de este nuevo ejemplo. Esto se realiza construyendo una vecindad similar a la de la figura anterior, sólo que de forma esférica, en el centro de este nuevo ejemplo. Si la dimensión es muy grande no habrá nada realmente cerca, sino que se encontrará todo en el borde de ésta, lo cual empeora bastante los resultados.
Para terminar y dar un poco de esperanza, os planteo una pregunta: ¿y si realmente no hicieran falta todas estas dimensiones?. Es decir, si de esas miles de dimensiones, pudiéramos quedarnos con las importantes. Y más aún ¿y si pudiéramos eliminar de golpe algunas?
Anteriormente, veíamos en nuestro ejemplo, que una persona podía describirse como un punto en un espacio de cuatro dimensiones. La idea era, a partir de muchas muestras con cuatro atributos cada una, determinar el nivel de estudios de una persona, es decir, si tenía estudios superiores o no.
Antes de ponerse manos a la obra y resolver el problema, sería interesante averiguar si ciertos atributos pueden ser eliminados. Por ejemplo, es muy probable que el peso y la altura no sean independientes, es decir, que para valores similares de peso, encontraremos en general valores similares de altura. Estos dos atributos pueden verse combinados en una sola, a la que podríamos llamar, por ejemplo, complexión.
Si damos un paso más, tal vez el nivel de ingresos tenga menos importancia de la que creemos a la hora de determinar si una persona tiene estudios universitarios, por lo que puede ser eliminado directamente. Nuestra persona pasaría a tener ahora dos dimensiones en lugar de cuatro.
persona' = (complexión, ingresos)
La misión de las técnicas de reducción de dimensiones es esa: obtener una representación más compacta, intentando mitigar los efectos de la maldición que asola a los espacios de alta dimensión. En concreto, cuando hablábamos de combinar atributos, las técnicas se denominan como extracción de características. Si por el contrario se desea encontrar un grupo de características de entre las originales, se trata de técnicas de selección de características. En cualquier caso, existirá un error, ya sea porque a la hora de representar los datos en una dimensión inferior se pierda información, o por la degradación de las técnicas si se mantiene la dimensionalidad inicial.
Y esto es todo por hoy. La semana que viene, volveré, con algo mucho más light y amigable.
Como dirían los entrevistados de Punset: "No es tan sencillo"
Esta semana vamos a darle un rápido repaso a cómo las máquinas, ordenadores, son capaces de aprender. Había pensado ponerle de título a la entrada "Ordenadores que aprenden", pero, seamos sinceros, la palabra ordenador suena fatal, mientras que máquina aporta al título un aspecto duro y, sobre todo, sexy.
Para entender como un ordenador aprende algo, es necesario saber su funcionamiento básico. Una computadora ejecuta programas, que son secuencias de instrucciones previamente programadas. Estas instrucciones no son muy distintas a las de una calculadora programable. Básicamente, a una velocidad increíble, el ordenador está leyendo números de memoria, operando con ellos y almacenándolos de nuevo para un uso posterior. La pregunta que planteo es ¿qué grado de aprendizaje puede asumir un ordenador, si su comportamiento viene definido por una secuencia de instrucciones de este estilo?
Bien, para un programa dado, sus instrucciones no se ejecutan siempre de la misma manera porque existe un elemento variable: los parámetros. Día a día, a veces sin darnos cuenta, comunicamos parámetros al ordenador. La dirección de una web, a la hora de introducirla en la barra del navegador, es un parámetro, y en función de su valor, la respuesta del programa será distinta. Nada más lejos de la realidad, este texto que escribo es un parámetro que estoy variando, luego el sistema de gestión de contenidos del blog, dependiendo de su contenido, lo transformará a un formato presentable (y si, esta vez con los párrafos justificados). La gracia de estos parámetros es que un cambio en sus valores pueden producir una respuesta diferente, sin necesidad de cambiar el programa subyacente.
Vale, ha quedado claro que los ordenadores pueden actuar de una manera u otra según los parámetros que se le introducen, pero no he dicho qué puede aprender un ordenador. Está claro que introducir la URL en el navegador no se presta a mucho aprendizaje (¿seguro?) y el texto que escribo es un simple bulto que se arrastra a lo largo de Internet (repito, ¿seguro?). Dar una definición de aprendizaje es compleja, incluso para seres humanos, y su generalización al ámbito computacional también lo es.
A grosso modo, se denomina aprendizaje automático (machine learning) al campo de la computación que se encarga de dar a los ordenadores la capacidad de aprender sin ser explícitamente programados para ello. Veamos algunos ejemplos de lo que puede aprender a hacer un ordenador:
Reconocer texto en general, ya sea manuscrito o tipografiado.
Reconocer caras.
Diagnóstico de enfermedades.
Selección de perfiles de personal.
Determinar si una transacción bancaria es fraudulenta.
Corregir el texto que escribimos en la pantalla táctil de un móvil (dios, esta si que me gusta)
...
A las tareas anteriores podemos añadir conducir, andar o incluso componer música (si, si Conde Chócula me lo permite, algún día haré una entrada sobre música generativa). En general un ordenador es capaz de aprender cualquier tarea cuyo conocimiento pueda verse de manera formal. Ahora bien, no podemos programar, es decir cambiar explícitamente las instrucciones que sigue el programa, pero sí podemos modificar los parámetros de un programa ya escrito. Pero claro, entonces necesitaría un programa para cada tarea de la lista anterior, es decir no puede usarse la misma técnica para reconocer texto que para reconocer caras o corregir texto mal escrito.
MENTIRA
Imaginaos la situación. Una letra, al igual que un texto escaneado, es una imagen. Una imagen es algo que está escrito en el idioma del ordenador. Por simplicidad, centrémonos en el reconocimiento de caracteres manuscritos. Si cada carácter esta contenido en una imagen en blanco y negro, existen ciertos píxeles que están en blanco y otros que estan en negro, lo cual puede verse como una matriz cuyas celdas pueden tomar valores de 0 para el negro o 1 para el blanco (o al revés, como más os plazca).
Una vez formalizada la entrada, vosotros, lectores míos, ¿que más hace falta para que el ordenador sea capaz de, a partir de la imagen, averiguar el carácter que representa?. Pensad como aprenderíais vosotros las letras del abecedario (¡dejadlo en los comentarios!), yo os voy a contar cómo lo haría el ordenador.
En primer lugar se construye un conjunto de entrenamiento, que se caracteriza porque para cada imagen se dispone del resultado, es decir del carácter que representa la letra contenida en la imagen. Una vez establecido, se procede a mostrar una y otra vez estos ejemplos al ordenador, el cual produce un resultado. La dinámica es la siguiente: si el programa se equivoca, modifica sus parámetros para evitar volver a cometer el error en un futuro.
Después de varias pasadas, cuyo número, entre otros factores, depende del número de ejemplos, el programa ha aprendido con más o menos "nota" los ejemplos. Si os dais cuenta, este procedimiento se asemeja bastante a los malvados ejercicios que mandan antes de hacer un examen. Genial, sois un ordenador y os sabéis de puta madre los ejercicios que habéis memorizado una y otra vez, pero ha llegado la hora del examen. El examen se realiza con otros ejercicios diferentes, el conjunto de test. Estos ejemplos no han sido vistos nunca por parte del programa y sirven únicamente para ver cuantos aciertos se tienen con datos desconocidos, lo cual da una medida de lo bien que nuestro programa ha aprendido lo que queríamos enseñarle.
Bueno señores, el problema del reconocimiento de caracteres es un problema de aprendizaje supervisado, porque se indica al método cuales han sido sus errores diciéndole la respuesta cada vez que intenta adivinar el resultado. Además se trata de un problema de clasificación, porque se trata de averiguar a que clase pertenecen las distintas imágenes, que en este caso son las letras del abecedario. La clave es que existen técnicas (de aprendizaje automático) que resuelven problemas de este tipo, las cuales de manera transparente al usuario (no hay que cambiar el comportamiento del método), dada una base de ejemplos y una representación adecuada de la entrada (en el caso anterior una matriz) y una salida (la clase, cualquiera de las letras del abecedario) son capaces de ajustar los parámetros para que en el futuro clasifique datos que no ha visto nunca.
En cuanto a las técnicas empleadas para este tipo de problema, podemos hablar de redes neuronales. En este caso los parámetros a ajustar son los potenciales de activación entre las neuronas, recordando un poco el funcionamiento de éstas en el sistema nervioso.
Otra técnica interesante son los árboles de clasificación, los cuales crean una estructura en forma de árbol en la cual a cada paso se realiza una pregunta sobre los datos. Aunque no son recomendables para el problema del reconocimiento de caracteres, un árbol de decisión podría ser perfectamente útil para diagnóstico de enfermedades, en cuyo caso las preguntas recordarían a las que realiza un médico: ¿es su temperatura superior a 37ºC?, ¿cuál es el recuento de leucocitos en sangre?, etc.
Finalmente, una de las técnicas empleadas para clasificación son las máquinas de vectores de soporte (support vector machines). Aquí os dejo un vídeo en el que se intenta clasificar dos tipos de puntos, los rojos y los azules. El problema es que no podemos, en dos dimensiones, separar las clases mediante una linea recta, lo cual interesa bastante, porque es bastante fácil trabajar con ellas (o con planos, o cualquier generalización en un espacio de dimensión superior). El truco que emplea esta técnica puede verse en el vídeo (si no os apetece saltadlo, simplemente quería mencionar esta técnica porque me parece una verdadera fumada, cualquier duda que tengáis preguntadla en los comentarios)
El truco parte de la idea de que si puedo tener más dimensiones (en el vídeo se pasa de dos, plano, a tres, espacio) también tengo más probabilidades de encontrar una superficie recta que separe a mis puntitos.
Hasta ahora hemos dado por supuesto que a la hora de enseñar al ordenador, se conoce la clase a la que pertenece el ejemplo. Esto se puede ver en el caso anterior en que para cada imagen también se sabía la letra que era realmente. Ahora bien, existen casos en los que lo que se persigue no es determinar a qué clase pertenece el ejemplo, sino agrupar los ejemplos según sus características. La situación en este nuevo problema sería encontrar en el caso de una empresa de telefonía móvil, perfiles de usuario. Suponemos que tenemos cierta información sobre cada cliente (su edad, tiempo en la compañía, consumo, etc) y queremos encontrar grupos para hacer publicidad más específica (sí señores, Google también hace algo similar con los anuncios). Si la clasificación puede llegar a ser compleja, el agrupamiento o aprendizaje no supervisado lo es más. Para dar una pequeña introducción planteo una serie de problemas que adolecen estas técnicas:
¿Cuantos grupos hay? Precisamente muchas técnicas requieren el número de grupos que hay que encontrar. En algunos casos puede ser conocido y en otros no, como es el caso de los perfiles de clientela.
¿Cómo se mide el parecido entre los elementos a agrupar? Este problema se puede paliar cuando hay poca información, pero conforme la información aumenta (el número de dimensiones del espacio en el que se encuentran los elementos a agrupar aumenta) las técnicas de medida de similitud degradan por el fenómeno conocido como la maldición de la dimensionalidad (curse of dimensionality).
¿Son necesarios todos los elementos? ¿Qué hacemos con los que sobran? Seguro que recordáis en estadística que a veces al pintar una gráfica había un punto loco que se alejaba del resto de la población. En ese caso el profesor(a) lo que solía deciros es que lo borrarais. Para problemas pequeños esta misma técnica puede aplicarse, pero de nuevo ¿cómo es posible medir que hay un elemento muy diferente al resto, cuando no eres capaz (para problemas grandes) de saber con fiabiliadad si son parecidos?
¿Cómo se sabe que los grupos son correctos? Antes, en aprendizaje supervisado podíamos dejar algunos ejemplos para probar cómo se comportaba el programa con datos no vistos anteriormente. Para aprendizaje no supervisado la comprobación no puede tener en cuenta esa información.
Para ser sincero, hay mucho más que decir sobre este tema. Por ejemplo, no hemos hablado de cómo predecir en el futuro el valor que tomará una determinada magnitud, mediante el estudio previo de lo sucedido en el pasado.
En general, existen multitud de técnicas de aprendizaje que evitan reprogramar la solución y son capaces de aprender a partir de los datos disponibles. Con esta entrada lo que espero haber conseguido es eliminar un poco el velo que cubre el aprendizaje computacional, sin haber caído en fórmulas ni tecnicismos.
Me gustaría que, a partir de ahora, sepáis que la manera que tiene un ordenador de aprender a partir de los datos, se fundamenta en la variación de sus parámetros. Los parámetros óptimos pueden encontrarse tras un entrenamiento o a partir de lo parecidos que son los ejemplos entre sí. De cualquier manera, si os pica la curiosidad, no dudeís en comentarlo abajo.
Este viernes retomo la dinámica de semanas anteriores y vuelvo a hablar sobre matemáticas de andar por casa. Hoy abordaremos el conjunto de Mandelbrot como caso particular de estructura fractal, de sus propiedades y si la existencia de este tipo de entidades son un descubrimiento de la realidad o es una invención de nuestras mentes.
El conjunto de Mandelbrot, como buen conjunto, es una colección de entidades que no se repiten. En este caso los miembros del conjunto son números complejos. A su vez, un número complejo puede verse como una extensión sobre los números reales. Si estos últimos pueden representarse, por así decirlo, con un único número (por ejemplo, 2.2345), los números complejos tienen una componente adicional, la parte imaginaria, que es denotada por la letra i. Por lo tanto, un número complejo se representa mediante dos "números", como puede ser 2.2345 + 2.8i. En este caso puede verse que el primer número es la parte real del número complejo y la segunda es (la que se multiplica por i)la imaginaria. En general, dado que se necesitan dos componentes para representar un número complejo, podemos verlos como puntos en el plano. El caso anterior sería un punto con coordenadas (2.2345, 2.8).
Introducido esto, podemos olvidarnos de los números complejos y razonar con ellos como si fueran puntos en el plano (este plano recibe el nombre de plano de Argand).
Pues señoritos y señoritas, la expresión anterior es el corazón del conjunto de Mandelbrot. ¿Pero no habías dicho que un conjunto era una colección de elementos? Efectivamente, pero esa colección se puede expresar de varias formas. Una definción es extensional cuando explícitamente se dicen los elementos que forman parte del conjunto. Por ejemplo: el conjunto de las provincias de la Comunidad Valenciana definido extensionalmente sería: {Alicante, Valencia, Castellón}. Sin embargo, un conjunto puede definirse de manera intensional cuando proporcionamos los medios para determinar si un elemento pertenece o no al conjunto. Por ejemplo: PAR es el conjunto de los números pares. Sabemos cuando un número es par (cuando el resto tras dividirlo entre 2 es cero) por lo que podemos comprobar para todos los elementos (en este caso números) si son pares. Por lo general las definiciones extensionales se suelen dar para conjuntos finitos y pequeños y las intensionales constituyen la única manera de definir conjuntos infinitos en su totalidad.
El conjunto de Mandelbrot, a partir de ahora lo denotaremos como M, se construye mediante las relaciones expuestas en la fórmula anterior. Básicamente c pertenece a M si tras aplicar la fórmula anterior el valor del z_i correspondiente no tiende a infinito. Habrá valores que tomen muy rápidamente un valor muy grande. Otros, por el contrario, tardaran más. En cualquier caso, es posible saber si un c dado está o no dentro de M. Aún a sabiendas de que cada ecuación disminuye las visitas de la entrada a la mitad, mostraré un breve ejemplo de cómo se calculan los cuatro primeros elementos del conjunto de Mandelbrot.
Si al cabo de un tiempo alguno z_i crece demasiado y se escapa al infinito, entonces el c empleado no pertenece a M. Dado que c puede verse como un punto en dos dimensiones, puede pintarse. Los puntos que no se van al infinito, es decir los miembros, se pintan de color negro y los que sí se alejan, se pintan de color blanco.
Conjunto de Mandelbrot, extraído de [1]
Antes de continuar, tal vez el lector haya visto este mismo diagrama pero en color. El color indica, para los puntos de la frontera, lo rápido que transforman en infinito, aquí por simplicidad sólo nos quedaremos con aquellos valores de c para los cuales ese fenómeno no se presenta.
De manera descriptiva podemos observar una serie de regiones, el gran cuerpo de la derecha, otro menor a la izquierda y dos verrugas idénticas, situadas arriba y abajo del cuerpo central. A su vez, si ampliáis la imagen, las regiones se parecen a distintas escala.
Este fenómeno mediante el cual unas regiones a una escala determinada se parecen a otras con otra escala diferente se conoce como autosimilitud, que puede ser total, cuando se hace zoom y la región ampliada es idéntica a la apreciada antes del aumento, o parcial, cuando la región se parece pero no es idéntica.
La autosimilitud del conjunto de Mandelbrot es parcial y puede verse (esta vez en color, que mola más) en el video que viene a continuación.
Después de este viaje psicodélico, creo que ya se tiene una visión, al menos intuitiva, de lo que es un fractal: un conjunto que se calcula mediante unas reglas concretas y que exhibe propiedades de autosmilitud a distintas escala y con distinto grado.
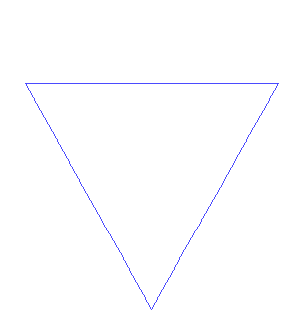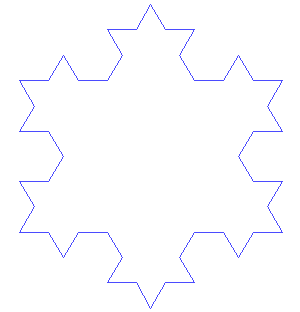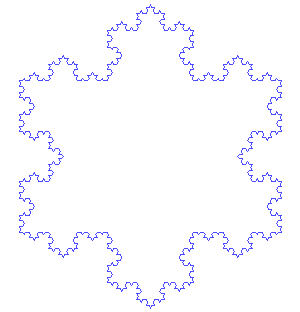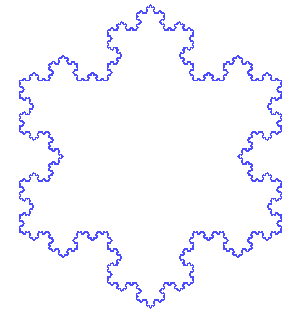
El conjunto de Mandelbrot no es ni de lejos el el único fractal conocido. A continuación puede verse el copo de nieve de Koch.
Copo de nieve de Koch a distintas escalas. Extraído de [2]
En este caso la autosimilitud es total. Lo que se ve en la animación superior es el refinamiento de la la figura, al igual que se veía en el vídeo anterior para el conjunto M. El parecido a un copo de nieve es evidente, pero no es ni de lejos el único fractal que encontramos en la naturaleza. A continuación pueden apreciarse un par de ejemplos:
Romanescu
Copo de nieve
Las imágenes anteriores exhiben una estructura fractal. La primera es una verdura, el Romanescu, y la segunda un copo de nieve. Por supuesto, esto es el mundo real y no podemos esperar que el grado de autosimilitud se repita ad infinitum,sino que debemos conformarnos con las limitaciones que la naturaleza impone a los procesos que originan estas estructuras. Otros ejemplos en la naturaleza pueden ser las nervaduras de las hojas o las conexiones entre ríos y sus afluentes. Para más información sobre los fractales en la naturaleza véase [3].
Me gustaría terminar esta entrada con una pequeña reflexión. Hemos visto cómo una expresión relativamente sencilla puede producir detalles inimaginablemente complejos y bellos. En este caso, dudo mucho de que el ser humano sea capaz de inventar la expresión sino que más bien se trata de un descubrimiento. El conjunto de Mandelbrot y muchas otras expresiones matemáticas, opino que tienen una existencia, como si de ideas platónicas se trataran, paralela a la realidad que nosotros percibimos. De vez en cuando alguien efectúa el descubrimiento y sólo entonces somos capaces de conocer esta realidad. Con esto no quiero decir que todos los resultados en matemáticas sean bellas ideas platónicas, ya que en muchos casos las matemáticas se emplean puramente como herramientas, introduciendo a nuestra voluntad elementos extraños que si bien son coherentes, no originan un descubrimiento, sino una invención por nuestra parte.


 con el permiso de Brassens, de Piaf, de Moustaki, de Ferré e incluso de Debussy, aunque eso queda más lejos. Fue lo que podría saberse un trovador, pero sin hablar en occitano ni delegar los recitales en otros.")